
Collecting logs
I should start from how fluentd collects logs. For these purposes, it has input plugins.
Input plugins say for themselves; they have only one job to do — collect logs from different sources and transform them into fluentd records. But they don’t output them immediately. Instead, they are being collected into buffers.
Let’s take a tail plug-in that can collect logs from files by tailing them. For that plugin, I’ve used the following configuration:
What does it do? Actually, it just runs tail -F, but a little smarter. It can
remember the last read position, supports different parsers, etc. Because of
this configuration, you will get a fluentd record for every single line in your
log files.
It will store all of them in fluentd buffer (which can be memory, a file, or anything else, if you have a plugin for that).
Delivering logs
When fluentd has parsed logs and pushed them into the buffer, it starts pull logs from buffer and output them somewhere else. For this, fluentd has output plugins.
Output plugin receives the fluentd record, parses it in an appropriate format for specified output (in our case Graylog) and delivers it via transport (http, udp, tcp, whatever…).
I’ll show an example for Graylog. Here is our configuration for outputting logs to Graylog:
The configuration says to its plugin and fluentd, that all the records from fluentd should be delivered to our Graylog server (GELF protocol).
Where was the slowdown
Turns out that input/output plugins and their configurations have nothing to do with slow delivering (by default).
The problem was in the buffer configuration itself. And, turns out, that the default configuration for buffer has specified interval by which it should be enqueued for delivering.
For our purpose, in elastic.io, we need to deliver logs from specific
containers as fast as possible. Turns out that you can change fluentd behavior
and how it should work with the buffer. The directive for controlling it is
called buffer.
So, let’s change our configuration for output plugin to force immediate sending of logs from the buffer:
You can change the behavior of the buffer in specific output plugins. I set
flush_mode to immediate, so right after fluentd record is pushed into the
buffer, it will be enqueued for delivering to our Graylog cluster.
Results
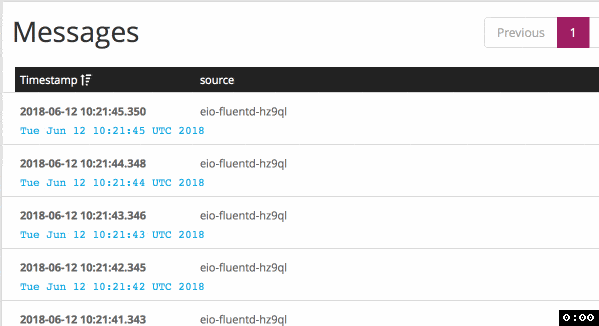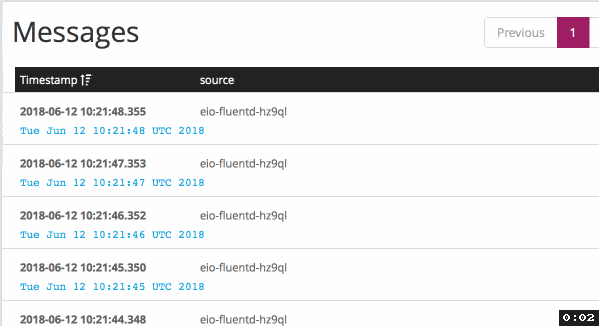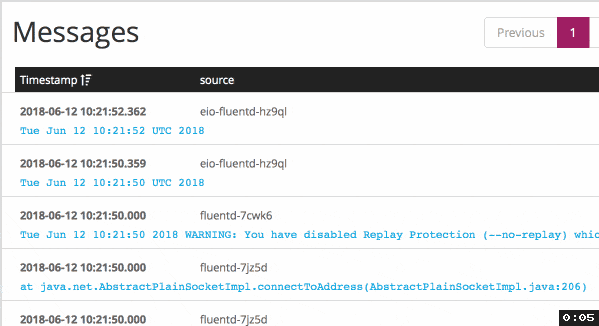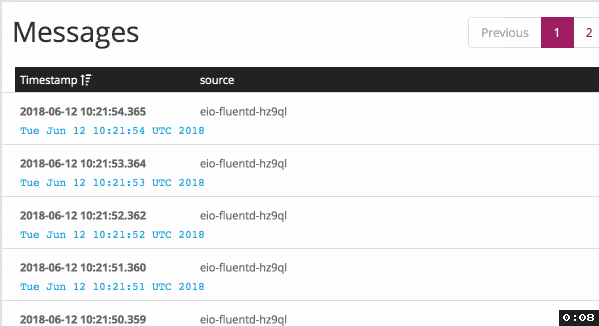
Before my changes in configuration (default behavior), it sends logs each 5 seconds:
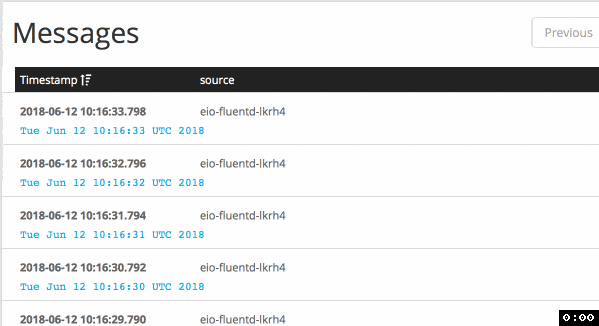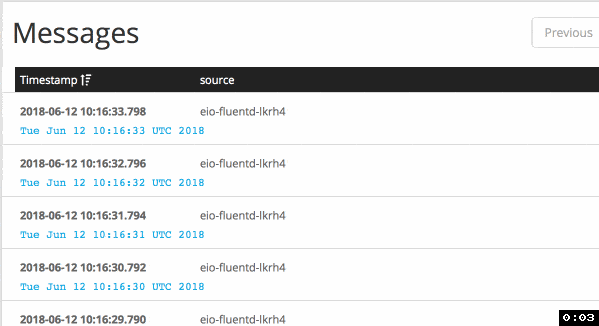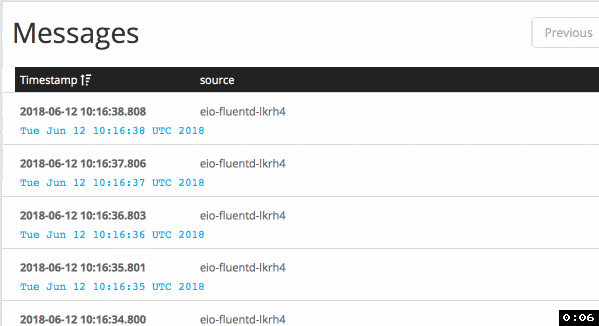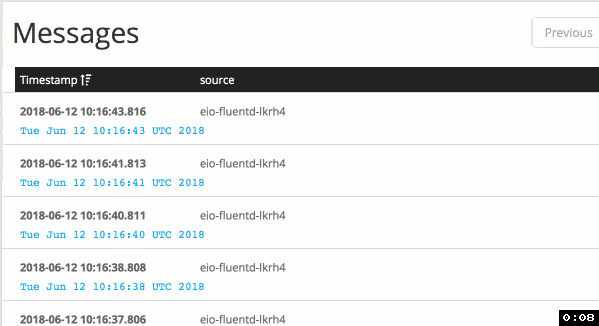
When I applied buffer configuration with immediate flush mode, it delivers
logs much faster:
I understand that fluentd describes this case in documentation, though I hope that this tip helps you to save your time for other work.
Eugene Obrezkov, Senior Software Engineer at elastic.io, Kyiv, Ukraine.



Comments